并发编程-ConcurrentHashMap(jdk1.8)介绍
ConcurrentHashMap简介
在使用HashMap时在多线程情况下扩容会出现CPU接近100%的情况,因为hashmap并不是线程安全的,通常我们可以使用在java体系中古老的hashtable类,该类基本上所有的方法都采用synchronized进行线程安全的控制,可想而知,在高并发的情况下,每次只有一个线程能够获取对象监视器锁,这样的并发性能的确不令人满意。
另外一种方式通过Collections的Map<K,V> synchronizedMap(Map<K,V> m)将hashmap包装成一个线程安全的map。比如SynchronzedMap的put方法源码为:
1 | public V put(K key, V value) { |
实际上SynchronizedMap实现依然是采用synchronized独占式锁进行线程安全的并发控制的。同样,这种方案的性能也是令人不太满意的。针对这种境况,Doug Lea大师不遗余力的为我们创造了一些线程安全的并发容器,让每一个java开发人员倍感幸福。相对于hashmap来说,ConcurrentHashMap就是线程安全的map,其中利用了锁分段的思想提高了并发度。
ConcurrentHashMap在JDK1.6的版本网上资料很多,有兴趣的可以去看看。
JDK 1.6版本关键要素:
- segment继承了ReentrantLock充当锁的角色,为每一个segment提供了线程安全的保障;
- segment维护了哈希散列表的若干个桶,每个桶由HashEntry构成的链表。
而到了JDK 1.8的ConcurrentHashMap就有了很大的变化,光是代码量就足足增加了很多。1.8版本舍弃了segment,并且大量使用了synchronized,以及CAS无锁操作以保证ConcurrentHashMap操作的线程安全性。至于为什么不用ReentrantLock而是Synchronzied呢?实际上,synchronzied做了很多的优化,包括偏向锁,轻量级锁,重量级锁,可以依次向上升级锁状态,但不能降级(关于synchronized可以看这篇文章),因此,使用synchronized相较于ReentrantLock的性能会持平甚至在某些情况更优,具体的性能测试可以去网上查阅一些资料。另外,底层数据结构改变为采用数组+链表+红黑树的数据形式。
关键属性及类
在了解ConcurrentHashMap的具体方法实现前,我们需要系统的来看一下几个关键的地方。
ConcurrentHashMap的关键属性
table
1
volatile Node<K,V>[] table;//装载Node的数组
作为ConcurrentHashMap的数据容器,采用懒加载的方式,直到第一次插入数据的时候才会进行初始化操作,数组的大小总是为2的幂次方。
nextTable
1
volatile Node<K,V>[] nextTable;//扩容时使用
平时为null,只有在扩容的时候才为非null
sizeCtl
1
volatile int sizeCtl;
该属性用来控制table数组的大小,根据是否初始化和是否正在扩容有几种情况:
当值为负数时:如果为-1表示正在初始化,如果为-N则表示当前正有N-1个线程进行扩容操作;
当值为正数时:如果当前数组为null的话表示table在初始化过程中,sizeCtl表示为需要新建数组的长度;
若已经初始化了,表示当前数据容器(table数组)可用容量也可以理解成临界值(插入节点数超过了该临界值就需要扩容),具体指为数组的长度n 乘以 加载因子loadFactor;
当值为0时:即数组长度为默认初始值。sun.misc.Unsafe U
在ConcurrentHashMapde的实现中可以看到大量的U.compareAndSwapXXXX的方法去修改ConcurrentHashMap的一些属性。这些方法实际上是利用了CAS算法保证了线程安全性,这是一种乐观策略,假设每一次操作都不会产生冲突,当且仅当冲突发生的时候再去尝试。而CAS操作依赖于现代处理器指令集,通过底层CMPXCHG指令实现。CAS(V,O,N)核心思想为:若当前变量实际值V与期望的旧值O相同,则表明该变量没被其他线程进行修改,因此可以安全的将新值N赋值给变量;若当前变量实际值V与期望的旧值O不相同,则表明该变量已经被其他线程做了处理,此时将新值N赋给变量操作就是不安全的,在进行重试。而在大量的同步组件和并发容器的实现中使用CAS是通过sun.misc.Unsafe类实现的,该类提供了一些可以直接操控内存和线程的底层操作,可以理解为java中的“指针”。该成员变量的获取是在静态代码块中:1
2
3
4
5
6
7
8static {
try {
U = sun.misc.Unsafe.getUnsafe();
.......
} catch (Exception e) {
throw new Error(e);
}
}
ConcurrentHashMap中关键内部类
Node
Node类实现了Map.Entry接口,主要存放key-value对,并且具有next域1
2
3
4
5
6
7static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
......
}另外可以看出很多属性都是用volatile进行修饰的,也就是为了保证内存可见性。
TreeNode
树节点,继承于承载数据的Node类。而红黑树的操作是针对TreeBin类的,从该类的注释也可以看出,也就是TreeBin会将TreeNode进行再一次封装1
2
3
4
5
6
7
8static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
......
}TreeBin
这个类并不负责包装用户的key、value信息,而是包装的很多TreeNode节点。实际的ConcurrentHashMap“数组”中,存放的是TreeBin对象,而不是TreeNode对象。
1
2
3
4
5
6
7
8
9
10
11static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
......
}ForwardingNode
在扩容时才会出现的特殊节点,其key,value,hash全部为null。并拥有nextTable指针引用新的table数组。
1
2
3
4
5
6
7
8static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
.....
}
CAS关键操作
在上面我们提及到在ConcurrentHashMap中会大量使用CAS修改它的属性和一些操作。因此,在理解ConcurrentHashMap的方法前我们需要了解下面几个常用的利用CAS算法来保障线程安全的操作。
tabAt
1
2
3
4// 该方法用来获取table数组中索引为i的Node元素。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}casTabAt
1
2
3
4
5// 利用CAS操作设置table数组中索引为i的元素
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}setTabAt
1
2
3
4// 该方法用来设置table数组中索引为i的元素
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
重点方法讲解
在熟悉上面的这核心信息之后,我们接下来就来依次看看几个常用的方法是怎样实现的。
实例构造器方法
在使用ConcurrentHashMap第一件事自然而然就是new 出来一个ConcurrentHashMap对象,一共提供了如下几个构造器方法:
1 | // 1. 构造一个空的map,即table数组还未初始化,初始化放在第一次插入数据时,默认大小为16 |
ConcurrentHashMap一共给我们提供了5种构造器方法,具体使用请看注释,我们来看看第2种构造器,传入指定大小时的情况,该构造器源码为:
1 | public ConcurrentHashMap(int initialCapacity) { |
这段代码的逻辑请看注释,很容易理解,如果小于0就直接抛出异常,如果指定值大于了所允许的最大值的话就取最大值,否则,在对指定值做进一步处理。最后将cap赋值给sizeCtl,关于sizeCtl的说明请看上面的说明,当调用构造器方法之后,sizeCtl的大小应该就代表了ConcurrentHashMap的大小,即table数组长度。tableSizeFor做了哪些事情了?源码为:
1 | /** |
通过注释就很清楚了,该方法会将调用构造器方法时指定的大小转换成一个2的幂次方数,也就是说ConcurrentHashMap的大小一定是2的幂次方,比如,当指定大小为18时,为了满足2的幂次方特性,实际上concurrentHashMapd的大小为2的5次方(32)。另外,需要注意的是,调用构造器方法的时候并未构造出table数组(可以理解为ConcurrentHashMap的数据容器),只是算出table数组的长度,当第一次向ConcurrentHashMap插入数据的时候才真正的完成初始化创建table数组的工作。
initTable方法
直接上源码:
1 | private final Node<K,V>[] initTable() { |
代码的逻辑请见注释,有可能存在一个情况是多个线程同时走到这个方法中,为了保证能够正确初始化,在第1步中会先通过if进行判断,若当前已经有一个线程正在初始化即sizeCtl值变为-1,这个时候其他线程在If判断为true从而调用Thread.yield()让出CPU时间片。正在进行初始化的线程会调用U.compareAndSwapInt方法将sizeCtl改为-1即正在初始化的状态。另外还需要注意的事情是,在第四步中会进一步计算数组中可用的大小即为数组实际大小n乘以加载因子0.75,可以看看这里乘以0.75是怎么算的,0.75为四分之三,这里n - (n >>> 2)是不是刚好是n-(1/4)n=(3/4)n,挺有意思的吧。如果选择是无参的构造器的话,这里在new Node数组的时候会使用默认大小为DEFAULT_CAPACITY(16),然后乘以加载因子0.75为12,也就是说数组的可用大小为12。
put方法
使用ConcurrentHashMap最长用的也应该是put和get方法了吧,我们先来看看put方法是怎样实现的。调用put方法时实际具体实现是putVal方法,源码如下:
1 | /** Implementation for put and putIfAbsent */ |
put方法的代码量有点长,我们按照上面的分解的步骤一步步来看。从整体而言,为了解决线程安全的问题,ConcurrentHashMap使用了synchronzied和CAS的方式。在之前了解过HashMap以及1.8版本之前的ConcurrenHashMap都应该知道ConcurrentHashMap结构图,为了方便下面的讲解这里先直接给出,如果对这有疑问的话,可以在网上随便搜搜即可。
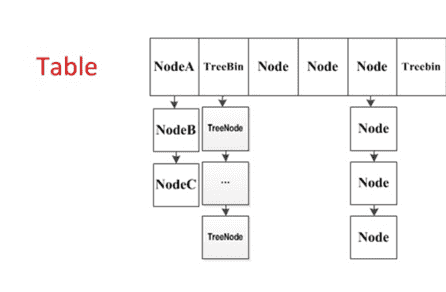
如图(图片摘自网络),ConcurrentHashMap是一个哈希桶数组,如果不出现哈希冲突的时候,每个元素均匀的分布在哈希桶数组中。当出现哈希冲突的时候,是标准的链地址的解决方式,将hash值相同的节点构成链表的形式,称为“拉链法”,另外,在1.8版本中为了防止拉链过长,当链表的长度大于8的时候会将链表转换成红黑树。table数组中的每个元素实际上是单链表的头结点或者红黑树的根节点。当插入键值对时首先应该定位到要插入的桶,即插入table数组的索引i处。那么,怎样计算得出索引i呢?当然是根据key的hashCode值。
- spread()重哈希,以减小Hash冲突
我们知道对于一个hash表来说,hash值分散的不够均匀的话会大大增加哈希冲突的概率,从而影响到hash表的性能。因此通过spread方法进行了一次重hash从而大大减小哈希冲突的可能性。spread方法为:
1 | static final int spread(int h) { |
该方法主要是将key的hashCode的低16位于高16位进行异或运算,这样不仅能够使得hash值能够分散能够均匀减小hash冲突的概率,另外只用到了异或运算,在性能开销上也能兼顾,做到平衡的trade-off。
2.初始化table
紧接着到第2步,会判断当前table数组是否初始化了,没有的话就调用initTable进行初始化,该方法在上面已经讲过了。
3.能否直接将新值插入到table数组中
从上面的结构示意图就可以看出存在这样一种情况,如果插入值待插入的位置刚好所在的table数组为null的话就可以直接将值插入即可。那么怎样根据hash确定在table中待插入的索引i呢?很显然可以通过hash值与数组的长度取模操作,从而确定新值插入到数组的哪个位置。而之前我们提过ConcurrentHashMap的大小总是2的幂次方,(n - 1) & hash运算等价于对长度n取模,也就是hash%n,但是位运算比取模运算的效率要高很多,Doug lea大师在设计并发容器的时候也是将性能优化到了极致,令人钦佩。
确定好数组的索引i后,就可以可以tabAt()方法(该方法在上面已经说明了,有疑问可以回过头去看看)获取该位置上的元素,如果当前Node f为null的话,就可以直接用casTabAt方法将新值插入即可。
4.当前是否正在扩容
如果当前节点不为null,且该节点为特殊节点(forwardingNode)的话,就说明当前concurrentHashMap正在进行扩容操作,关于扩容操作,下面会作为一个具体的方法进行讲解。那么怎样确定当前的这个Node是不是特殊的节点呢?是通过判断该节点的hash值是不是等于-1(MOVED),代码为(fh = f.hash) == MOVED,对MOVED的解释在源码上也写的很清楚了:
1 | static final int MOVED = -1; // hash for forwarding nodes |
5.当table[i]为链表的头结点,在链表中插入新值
在table[i]不为null并且不为forwardingNode时,并且当前Node f的hash值大于0(fh >= 0)的话说明当前节点f为当前桶的所有的节点组成的链表的头结点。那么接下来,要想向ConcurrentHashMap插入新值的话就是向这个链表插入新值。通过synchronized (f)的方式进行加锁以实现线程安全性。往链表中插入节点的部分代码为:
1 | if (fh >= 0) { |
这部分代码很好理解,就是两种情况:1. 在链表中如果找到了与待插入的键值对的key相同的节点,就直接覆盖即可;2. 如果直到找到了链表的末尾都没有找到的话,就直接将待插入的键值对追加到链表的末尾即可
6.当table[i]为红黑树的根节点,在红黑树中插入新值
按照之前的数组+链表的设计方案,这里存在一个问题,即使负载因子和Hash算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,甚至在极端情况下,查找一个节点会出现时间复杂度为O(n)的情况,则会严重影响ConcurrentHashMap的性能,于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高ConcurrentHashMap的性能,其中会用到红黑树的插入、删除、查找等算法。当table[i]为红黑树的树节点时的操作为:
1 | if (f instanceof TreeBin) { |
首先在if中通过f instanceof TreeBin判断当前table[i]是否是树节点,这下也正好验证了我们在最上面介绍时说的TreeBin会对TreeNode做进一步封装,对红黑树进行操作的时候针对的是TreeBin而不是TreeNode。这段代码很简单,调用putTreeVal方法完成向红黑树插入新节点,同样的逻辑,如果在红黑树中存在于待插入键值对的Key相同(hash值相等并且equals方法判断为true)的节点的话,就覆盖旧值,否则就向红黑树追加新节点。
7.根据当前节点个数进行调整
当完成数据新节点插入之后,会进一步对当前链表大小进行调整,这部分代码为:
1 | if (binCount != 0) { |
很容易理解,如果当前链表节点个数大于等于8(TREEIFY_THRESHOLD)的时候,就会调用treeifyBin方法将tabel[i](第i个散列桶)拉链转换成红黑树。
至此,关于Put方法的逻辑就基本说的差不多了,现在来做一些总结:
整体流程:
- 首先对于每一个放入的值,首先利用spread方法对key的hashcode进行一次hash计算,由此来确定这个值在 table中的位置;
- 如果当前table数组还未初始化,先将table数组进行初始化操作;
- 如果这个位置是null的,那么使用CAS操作直接放入;
- 如果这个位置存在结点,说明发生了hash碰撞,首先判断这个节点的类型。如果该节点fh==MOVED(代表forwardingNode,数组正在进行扩容)的话,说明正在进行扩容;
- 如果是链表节点(fh>0),则得到的结点就是hash值相同的节点组成的链表的头节点。需要依次向后遍历确定这个新加入的值所在位置。如果遇到key相同的节点,则只需要覆盖该结点的value值即可。否则依次向后遍历,直到链表尾插入这个结点;
- 如果这个节点的类型是TreeBin的话,直接调用红黑树的插入方法进行插入新的节点;
- 插入完节点之后再次检查链表长度,如果长度大于8,就把这个链表转换成红黑树;
- 对当前容量大小进行检查,如果超过了临界值(实际大小*加载因子)就需要扩容。
get方法
看完了put方法再来看get方法就很容易了,用逆向思维去看就好,这样存的话我反过来这么取就好了。get方法源码为:
1 | public V get(Object key) { |
代码的逻辑请看注释,首先先看当前的hash桶数组节点即table[i]是否为查找的节点,若是则直接返回;若不是,则继续再看当前是不是树节点?通过看节点的hash值是否为小于0,如果小于0则为树节点。如果是树节点在红黑树中查找节点;如果不是树节点,那就只剩下为链表的形式的一种可能性了,就向后遍历查找节点,若查找到则返回节点的value即可,若没有找到就返回null。
transfer方法
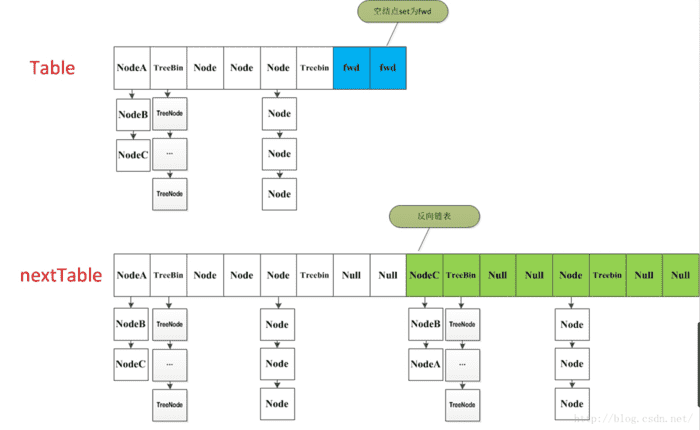
当ConcurrentHashMap容量不足的时候,需要对table进行扩容。这个方法的基本思想跟HashMap是很像的,但是由于它是支持并发扩容的,所以要复杂的多。原因是它支持多线程进行扩容操作,而并没有加锁。我想这样做的目的不仅仅是为了满足concurrent的要求,而是希望利用并发处理去减少扩容带来的时间影响。transfer方法源码为:
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
代码逻辑请看注释,整个扩容操作分为两个部分:
第一部分是构建一个nextTable,它的容量是原来的两倍,这个操作是单线程完成的。新建table数组的代码为:Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1],在原容量大小的基础上右移一位。
第二个部分就是将原来table中的元素复制到nextTable中,主要是遍历复制的过程。
根据运算得到当前遍历的数组的位置i,然后利用tabAt方法获得i位置的元素再进行判断:
- 如果这个位置为空,就在原table中的i位置放入forwardNode节点,这个也是触发并发扩容的关键点;
- 如果这个位置是Node节点(fh>=0),如果它是一个链表的头节点,就构造一个反序链表,把他们分别放在nextTable的i和i+n的位置上
- 如果这个位置是TreeBin节点(fh<0),也做一个反序处理,并且判断是否需要untreefi,把处理的结果分别放在nextTable的i和i+n的位置上
- 遍历过所有的节点以后就完成了复制工作,这时让nextTable作为新的table,并且更新sizeCtl为新容量的0.75倍 ,完成扩容。设置为新容量的0.75倍代码为
sizeCtl = (n << 1) - (n >>> 1),仔细体会下是不是很巧妙,n<<1相当于n右移一位表示n的两倍即2n,n>>>1左右一位相当于n除以2即0.5n,然后两者相减为2n-0.5n=1.5n,是不是刚好等于新容量的0.75倍即2n*0.75=1.5n。最后用一个示意图来进行总结(图片摘自网络):
与size相关的一些方法
对于ConcurrentHashMap来说,这个table里到底装了多少东西其实是个不确定的数量,因为不可能在调用size()方法的时候像GC的“stop the world”一样让其他线程都停下来让你去统计,因此只能说这个数量是个估计值。对于这个估计值,ConcurrentHashMap也是大费周章才计算出来的。
为了统计元素个数,ConcurrentHashMap定义了一些变量和一个内部类
1 | /** |
mappingCount与size方法
mappingCount与size方法的类似从给出的注释来看,应该使用mappingCount代替size方法 两个方法都没有直接返回basecount 而是统计一次这个值,而这个值其实也是一个大概的数值,因此可能在统计的时候有其他线程正在执行插入或删除操作。
1 | public int size() { |
addCount方法
在put方法结尾处调用了addCount方法,把当前ConcurrentHashMap的元素个数+1这个方法一共做了两件事,更新baseCount的值,检测是否进行扩容。
1 | private final void addCount(long x, int check) { |
总结
JDK6,7中的ConcurrentHashmap主要使用Segment来实现减小锁粒度,分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性,当要统计全局时(比如size),首先会尝试多次计算modcount来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回size。如果有,则需要依次锁住所有的Segment来计算。
1.8之前put定位节点时要先定位到具体的segment,然后再在segment中定位到具体的桶。而在1.8的时候摒弃了segment臃肿的设计,直接针对的是Node[] tale数组中的每一个桶,进一步减小了锁粒度。并且防止拉链过长导致性能下降,当链表长度大于8的时候采用红黑树的设计。
主要设计上的变化有以下几点:
- 不采用segment而采用node,锁住node来实现减小锁粒度。
- 设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。
- 使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。
- sizeCtl的不同值来代表不同含义,起到了控制的作用。
- 采用synchronized而不是ReentrantLock
并发编程-ConcurrentHashMap(jdk1.8)介绍