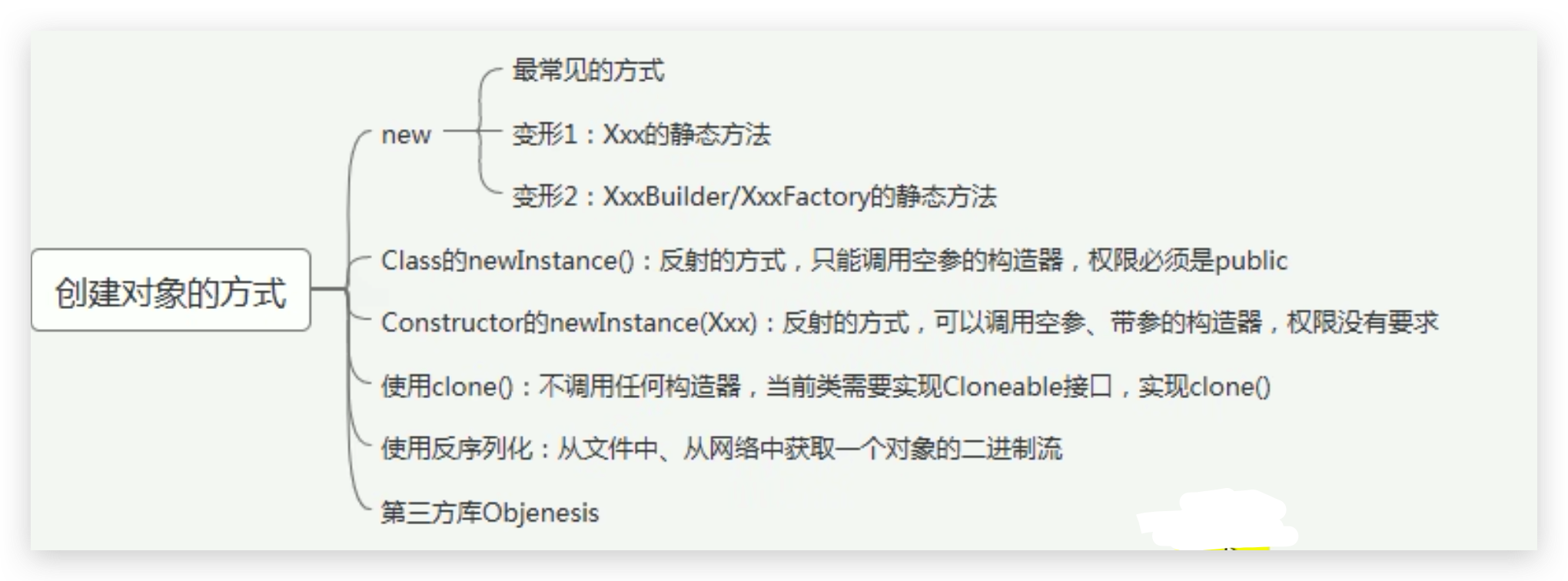
字符串的拼接操作
原理
- 常量与常量的拼接结果在常量池中(堆中划分的一块内存),原理是编译期优化
- 常量池中不会存在相同内容的变量
- 拼接前后,只要其中有一个是变量,结果就在堆中(区别于1中的堆,在常量池之外的堆中)。变量拼接的原理是StringBuilder
- 如果拼接的结果调用intern()方法,根据该字符串是否在常量池中存在,分为:
- 如果存在,则返回字符串在常量池中的地址
- 如果字符串常量池中不存在该字符串,则在常量池中创建一份,并返回此对象的地址
JVM-033-StringTable-String的概述和基本操作
String在jdk8及以前内部定义了final char value[]用于存储字符串数据。JDK9时改为final byte[] value
官方文档:http://openjdk.java.net/jeps/254
原因:
String类的当前实现将字符存储在char数组中,每个字符使用两个字节(16位)。
从许多不同的应用程序收集的数据表明,字符串是堆使用的主要组成部分,而且大多数字符串对象只包含拉丁字符(Latin-1)。这些字符只需要一个字节的存储空间,因此这些字符串对象的内部char数组中有一半的空间将不会使用,产生了大量浪费。
之前 String 类使用 UTF-16编码 的 char[] 数组存储,现在改为 byte[] 数组 外加一个编码标识存储。该编码表示如果你的字符集编码是ISO-8859-1或者Latin-1,那么只需要一个字节存。如果你是其它字符集编码,比如UTF-8,你仍然用两个字节存
结论:String再也不用char[] 来存储了,改成了byte [] 加上编码标记,节约了一些空间
同时基于String的数据结构,例如StringBuffer和StringBuilder也同样做了修改
1 | // jdk8及之前 |
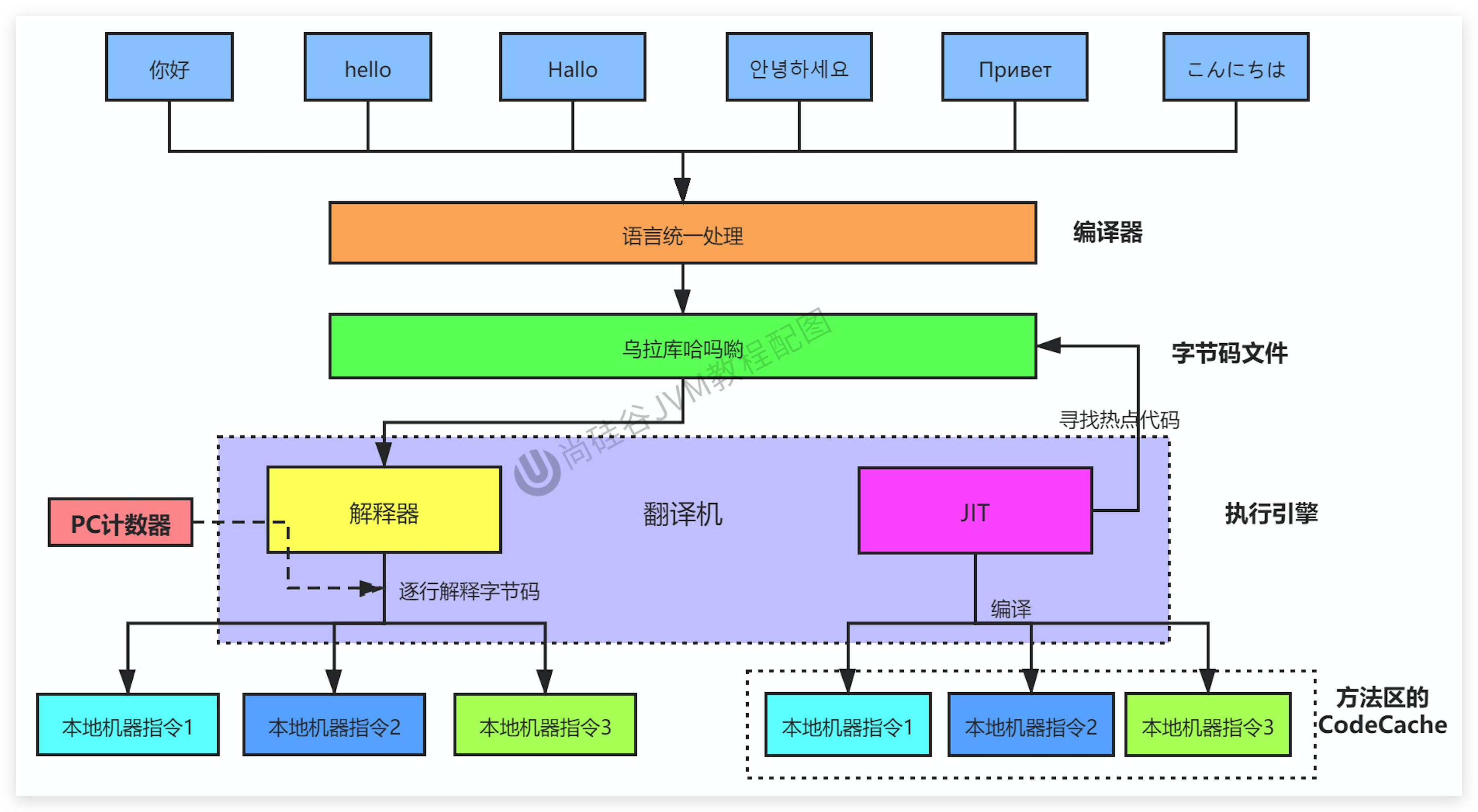
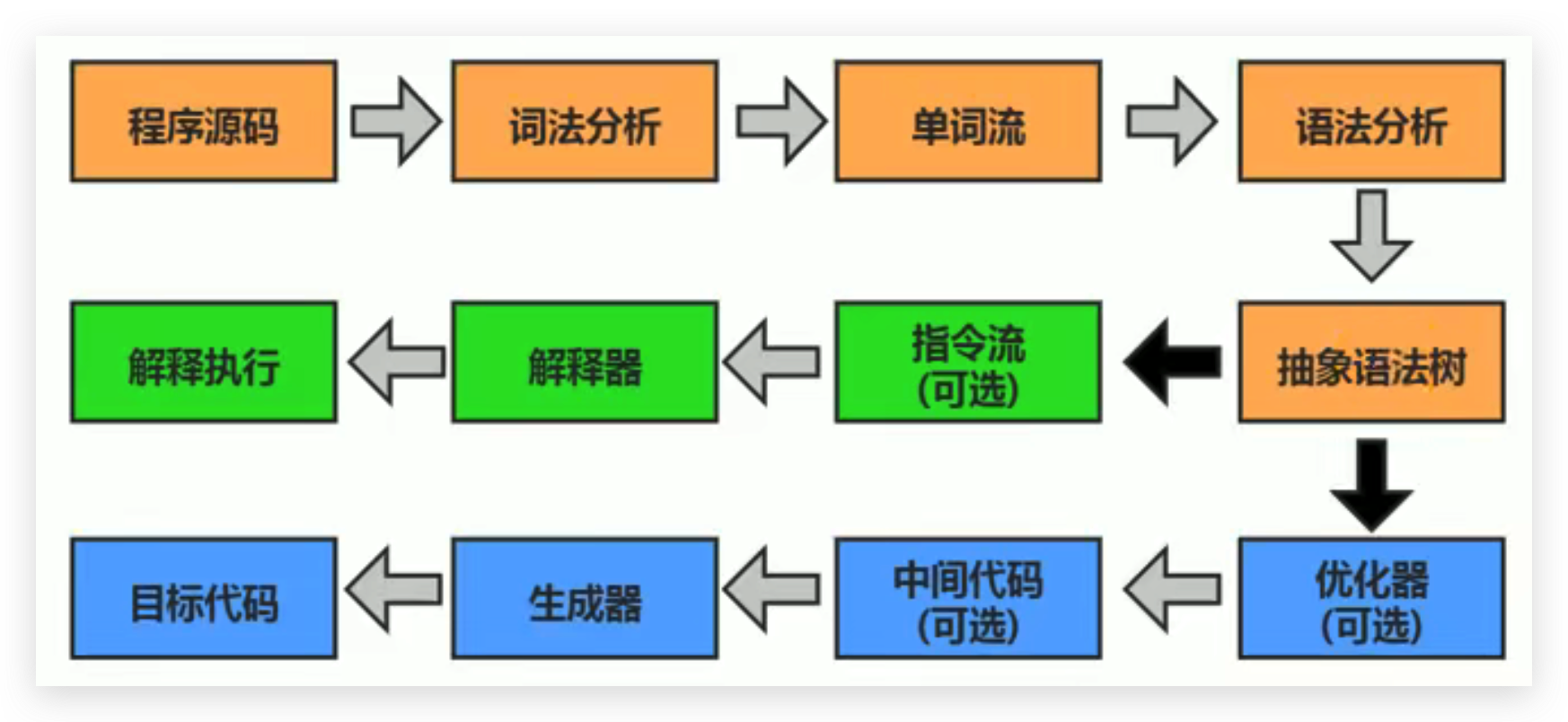
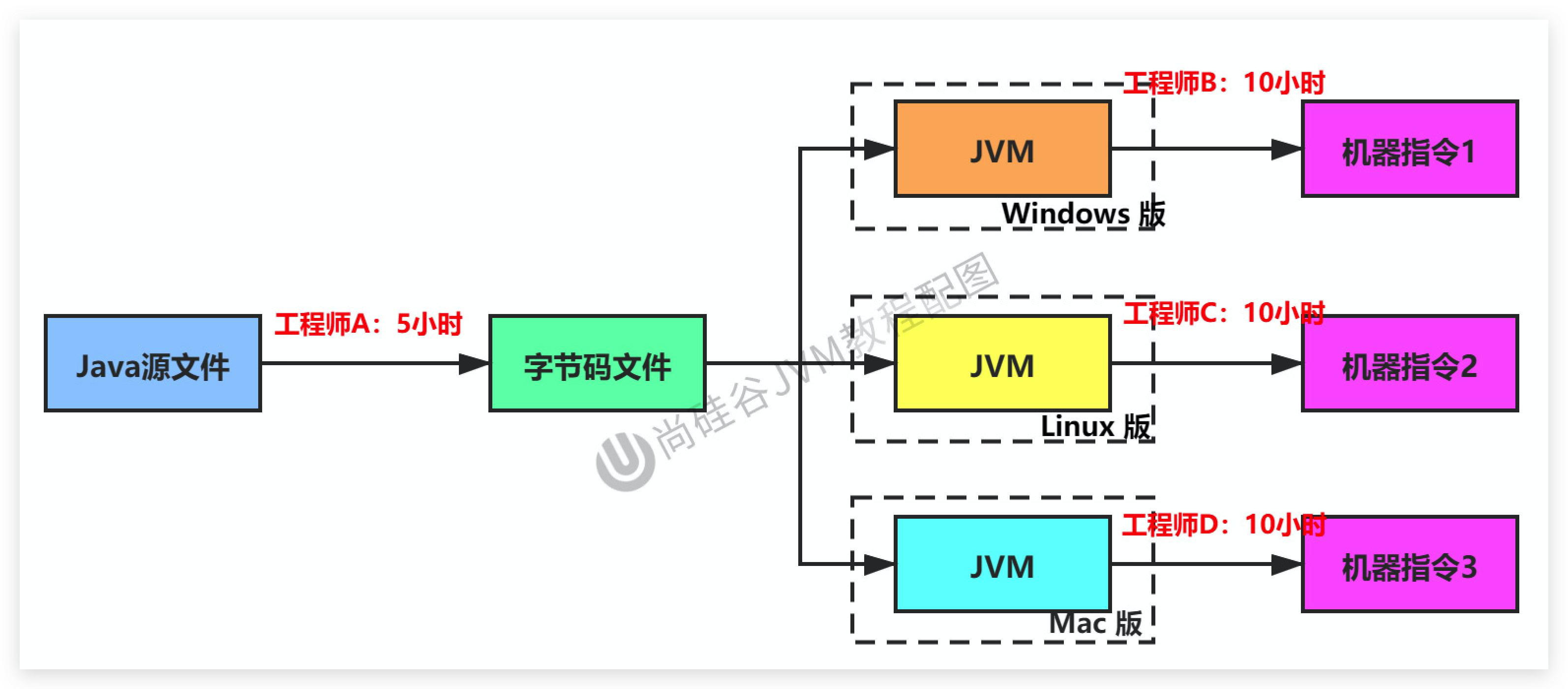
.java文件转变成.class文件的过程。JIT编译器,Just In Time Compiler)把字节码转变成机器码的过程。AOT编译器,Ahead of Time Compiler)直接把.java文件编译成本地机器代码的过程。(可能是后续发展的趋势)比较常见的编译器:
前端编译器:Sun 的 javac、Eclipse JDT中的增量式编译器(ECJ)。
JIT编译器:HotSpot VM的C1、C2编译器。
AOT 编译器:GNU Compiler for the Java(GCJ)、Excelsior JET。
JVM设计者们的初衷仅仅只是单纯地为了满足Java程序实现跨平台特性,因此避免采用静态编译的方式由高级语言直接生成本地机器指令,从而诞生了实现解释器在运行时采用逐行解释字节码执行程序的想法。
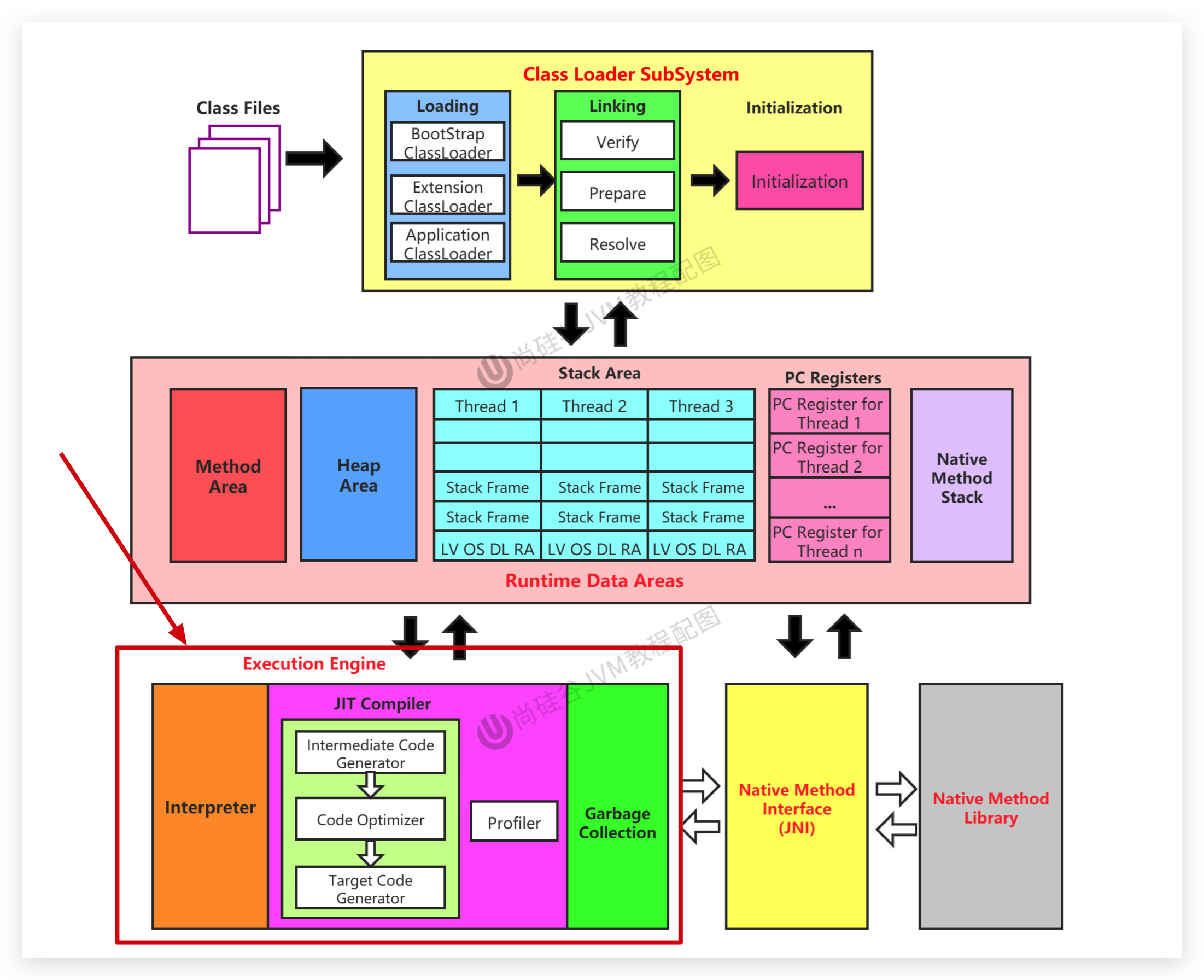
不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。
直接内存是在Java堆外的、直接向系统申请的内存区间。
来源于NIO(New IO / Non-Blocking IO),通过存在堆中的DirectByteBuffer操作Native内存
通常,访问直接内存的速度会优于Java堆。即读写性能高。
因此出于性能考虑,读写频繁的场合可能会考虑使用直接内存。
Java的NIO库允许Java程序使用直接内存,用于数据缓冲区
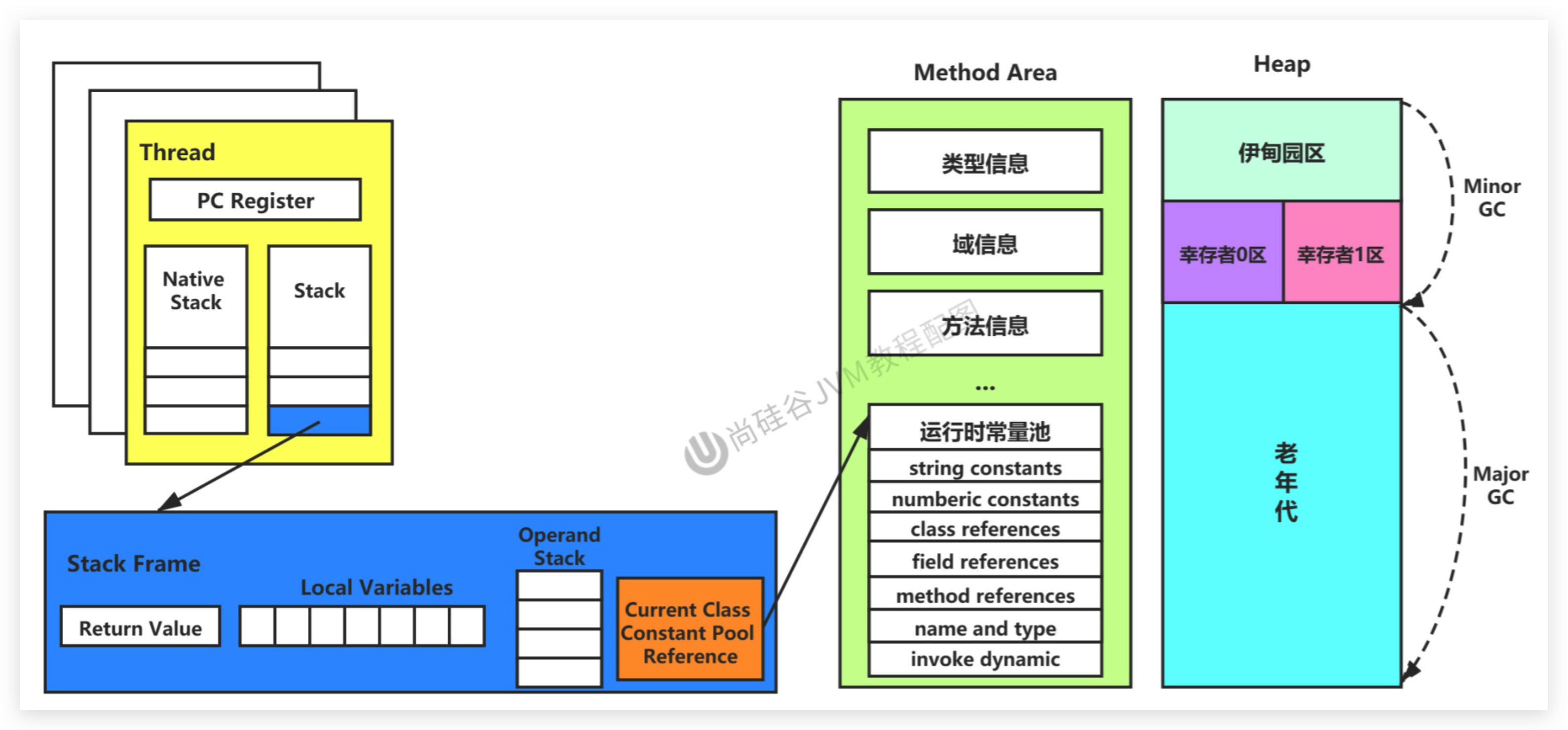
JVM-026-运行时数据区-对象的实例化内存布局与访问定位